 Boost
C++ Libraries
Boost
C++ Libraries
...one of the most highly
regarded and expertly designed C++ library projects in the
world.
— Herb Sutter and Andrei
Alexandrescu, C++
Coding Standards
Boost
C++ Libraries
...one of the most highly
regarded and expertly designed C++ library projects in the
world.
— Herb Sutter and Andrei
Alexandrescu, C++
Coding Standards


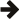
#include <boost/math/statistics/univariate_statistics.hpp> namespace boost{ namespace math{ namespace statistics { template<class Container> auto mean(Container const & c); template<class ForwardIterator> auto mean(ForwardIterator first, ForwardIterator last); template<class Container> auto variance(Container const & c); template<class ForwardIterator> auto variance(ForwardIterator first, ForwardIterator last); template<class Container> auto sample_variance(Container const & c); template<class ForwardIterator> auto sample_variance(ForwardIterator first, ForwardIterator last); template<class Container> auto mean_and_sample_variance(Container const & c); template<class Container> auto skewness(Container const & c); template<class ForwardIterator> auto skewness(ForwardIterator first, ForwardIterator last); template<class Container> auto kurtosis(Container const & c); template<class ForwardIterator> auto kurtosis(ForwardIterator first, ForwardIterator last); template<class Container> auto excess_kurtosis(Container const & c); template<class ForwardIterator> auto excess_kurtosis(ForwardIterator first, ForwardIterator last); template<class Container> auto first_four_moments(Container const & c); template<class ForwardIterator> auto first_four_moments(ForwardIterator first, ForwardIterator last); template<class Container> auto median(Container & c); template<class ForwardIterator> auto median(ForwardIterator first, ForwardIterator last); template<class RandomAccessIterator> auto median_absolute_deviation(ForwardIterator first, ForwardIterator last, typename std::iterator_traits<RandomAccessIterator>::value_type center=std::numeric_limits<Real>::quiet_NaN()); template<class RandomAccessContainer> auto median_absolute_deviation(RandomAccessContainer v, typename RandomAccessContainer::value_type center=std::numeric_limits<Real>::quiet_NaN()); template<class Container> auto gini_coefficient(Container & c); template<class ForwardIterator> auto gini_coefficient(ForwardIterator first, ForwardIterator last); template<class Container> auto sample_gini_coefficient(Container & c); template<class ForwardIterator> auto sample_gini_coefficient(ForwardIterator first, ForwardIterator last); }}}
The file boost/math/statistics/univariate_statistics.hpp is a
set of facilities for computing scalar values from vectors.
Many of these functionals have trivial naive implementations, but experienced programmers will recognize that even trivial algorithms are easy to screw up, and that numerical instabilities often lurk in corner cases. We have attempted to do our "due diligence" to root out these problems-scouring the literature for numerically stable algorithms for even the simplest of functionals.
Nota bene: Some similar functionality is provided in
Boost
Accumulators Framework. These accumulators should be used in real-time
applications; univariate_statistics.hpp should
be used when CPU vectorization is needed. As a reminder, remember that to actually
get vectorization, compile with -march=native
-O3
flags.
We now describe each functional in detail. Our examples use std::vector<double>
to hold the data, but this not required. In general, you can store your data
in an Eigen array, and Armadillo vector, std::array,
and for many of the routines, a std::forward_list.
These routines are usable in float, double, long double, and Boost.Multiprecision
precision, as well as their complex extensions whenever the computation is
well-defined. For certain operations (total variation, for example) integer
inputs are supported.
std::vector<double> v{1,2,3,4,5}; double mu = boost::math::statistics::mean(v.cbegin(), v.cend()); // Alternative syntax if you want to use entire container: mu = boost::math::statistics::mean(v);
The implementation follows Higham 1.6a. The data is not modified and must be forward iterable. Works with real and integer data. If the input is an integer type, the output is a double precision float.
std::vector<double> v{1,2,3,4,5}; Real sigma_sq = boost::math::statistics::variance(v.cbegin(), v.cend());
If you don't need to calculate on a subset of the input, then the range call is more terse:
std::vector<double> v{1,2,3,4,5}; Real sigma_sq = boost::math::statistics::variance(v);
The implementation follows Higham
1.6b. The input data must be forward iterable and the range [first,
last)
must contain at least two elements. It is not in general
sensible to pass complex numbers to this routine. If integers are passed as
input, then the output is a double precision float.
boost::math::statistics::variance
returns the population variance. If you want a sample variance, use
std::vector<double> v{1,2,3,4,5}; Real sn_sq = boost::math::statistics::sample_variance(v);
Computes the skewness of a dataset:
std::vector<double> v{1,2,3,4,5}; double skewness = boost::math::statistics::skewness(v); // skewness = 0.
The input vector is not modified, works with integral and real data. If the input data is integral, the output is a double precision float.
For a dataset consisting of a single constant value, we take the skewness to be zero by definition.
The implementation follows Pebay.
Computes the kurtosis of a dataset:
std::vector<double> v{1,2,3,4,5}; double kurtosis = boost::math::statistics::kurtosis(v); // kurtosis = 17/10
The implementation follows Pebay.
The input data must be forward iterable and must consist of real or integral
values. If the input data is integral, the output is a double precision float.
Note that this is not the excess kurtosis. If you require
the excess kurtosis, use boost::math::statistics::excess_kurtosis. This function simply subtracts
3 from the kurtosis, but it makes eminently clear our definition of kurtosis.
Simultaneously computes the first four central moments in a single pass through the data:
std::vector<double> v{1,2,3,4,5}; auto [M1, M2, M3, M4] = boost::math::statistics::first_four_moments(v);
Computes the median of a dataset:
std::vector<double> v{1,2,3,4,5}; double m = boost::math::statistics::median(v.begin(), v.end());
Nota bene: The input vector is modified. The calculation
of the median is a thin wrapper around the C++11 nth_element. Therefore, all requirements
of std::nth_element are inherited by the median calculation.
In particular, the container must allow random access.
Computes the median absolute deviation of a dataset:
std::vector<double> v{1,2,3,4,5}; double mad = boost::math::statistics::median_absolute_deviation(v);
By default, the deviation from the median is used. If you have some prior that the median is zero, or wish to compute the median absolute deviation from the mean, use the following:
// prior is that center is zero: double center = 0; double mad = boost::math::statistics::median_absolute_deviation(v, center); // compute median absolute deviation from the mean: double mu = boost::math::statistics::mean(v); double mad = boost::math::statistics::median_absolute_deviation(v, mu);
Nota bene: The input vector is modified. Again the vector
is passed into a call to nth_element.
Compute the Gini coefficient of a dataset:
std::vector<double> v{1,0,0,0}; double gini = boost::math::statistics::gini_coefficient(v); // gini = 3/4 double s_gini = boost::math::statistics::sample_gini_coefficient(v); // s_gini = 1. std::vector<double> w{1,1,1,1}; gini = boost::math::statistics::gini_coefficient(w.begin(), w.end()); // gini = 0, as all elements are now equal.
Nota bene: The input data is altered: in particular, it
is sorted. Makes a call to std::sort, and
as such requires random access iterators.
The sample Gini coefficient lies in the range [0,1], whereas the population Gini coefficient is in the range [0, 1 - 1/ n].
Nota bene: There is essentially no reason to pass negative
values to the Gini coefficient function. However, a use case (measuring wealth
inequality when some people have negative wealth) exists, so we do not throw
an exception when negative values are encountered. You should have very
good cause to pass negative values to the Gini coefficient calculator. Another
use case is found in signal processing, but the sorting is by magnitude and
hence has a different implementation. See absolute_gini_coefficient
for details.